

Оглавление
Часть 1-я: Как всё начиналось — 1940–1989, а также о первых 1-кристальных процессорах.
Часть 2-я: Наши дни — 1990–2010, а также пример современного техпроцесса.
Часть 3-я: Анализ и перспективы — 70 лет микроэлектроники в таблицах и графиках, новый шаг Intel, макрохитрости микроэлектроники, и о будущем.
Статья одной страницейОбщим взглядом…Данные с IC Knowledge, если не указано иное.
 Технорма наиболее сложных микросхем. Падает также их цена — правда, не вдвое (исходя из примерно половинной площади чипа для данного числа транзисторов — за исключением последних техпроцессов…), а примерно в 1,5 раза при каждом переходе на очередной техпроцесс (т. к. он сложнее и дороже на каждую единицу площади). По какой причине физическая длина затвора (не только для ЦП Intel) оказывается меньше технормы — читайте ниже. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Технорма для ЦП Intel. По мнению компании, 15-нанометровый техпроцесс, возможно, станет первым, где будет применяться «экстремальный» ультрафиолет (EUV), если он окажется экономически оправданным. До сих пор чрезвычайная дороговизна (даже по меркам фотолитографов) сдерживала его внедрение, которое 10 лет назад пророчили уже для 45-нанометрового процесса. Основные причины — необходимость в совершенно новом источнике излучения, новой зеркальной (а не линзовой) оптике и полном вакууме в рабочей зоне. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Площади кристаллов наиболее сложных микросхем процессоров и памяти на указанный год. В 1990-е годы тенденция увеличения площади на 14% в год (чёрная линия) остановлена. Впрочем, самые сложные кристаллы ГП и серверных ЦП достигают 400–500 мм², но и эта цифра не растёт уже лет пять, хотя почти все производители уже успели с 90-х перейти на 300-миллиметровые пластины, позволяющие производить с той же массовостью и ценой даже такие большие кристаллы. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Число транзисторов на кристалле ИС как следствие уменьшения технормы и увеличения площади кристалла. Видно, что первоначальная тенденция 2-кратного роста в год, по которой строил свои рассуждения Гордон Мур, была в прямом смысле весьма крутой. Но с 70-х и микросхемы ДОЗУ (теперь — и флэша), и процессоры продолжили её с меньшими темпами — 58% и 38% в год. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Число слоёв, требующих маски. До введения двойного шаблонирования равно числу самих масок. Каждая маска требует 7–8 производственных операций, а также контрольно-измерительные и транспортные. Примерно 20% слоёв в каждом кристалле (элементы транзисторов и первые слои дорожек и изоляторов) являются «критическими» — т. е. выполнены с номинальной технормой для данного техпроцесса. Остальным достаточно быть всё более грубыми по мере удаления вверх от транзисторов (см. иллюстрацию воздушных зазоров), т. к. верхние уровни металла, как правило, поставляют питание и синхронизацию, так что особой плотности проводников им не требуется. Таким образом наиболее дорогие технологии изготовления применяются только для части слоёв, но даже это не спасает от растущей сложности техпроцессов, особенно с 2000-х годов. 20 лет назад такое уже было с технологией БиКМОП (гибрид биполярной и КМОП), из-за чего от неё отказались (правда, Intel успела выпустить на ней 486DX4, Pentium и P.Pro, а Sun Microsystems — SuperSPARC). Сегодня от взрывного роста сложности не страдают пока только динамическая и (в меньшей степени) флеш-память. Сверхбыстрым SiGe-чипам высокая стоимость не сильно мешает, т. к. их изготавливают малыми партиями для военных и авиакосмических применений. В среднем число масок увеличивается на 2 с каждым техпроцессом, т. е. примерно за 2 года. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
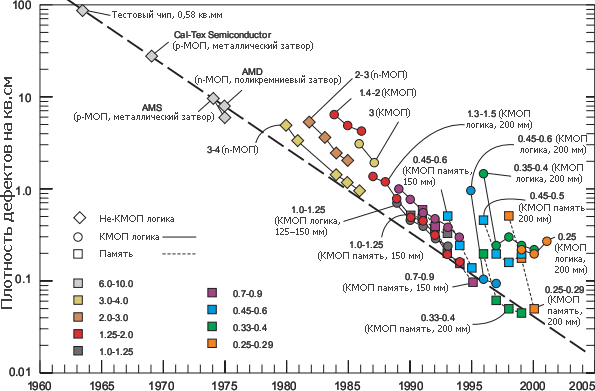 Плотность дефектов на 1 см² площади кристалла от наиболее продвинутых фабов при финальном тестировании. Жирными цифрами указана технорма в микронах, в скобках — диаметр пластин. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Снова плотность дефектов, но конкретно для чипов Intel. По её утверждению — также отложенная по логарифмической шкале (как и на графике выше), только без шкалы. ;) Данные для 45- и 32-нанометрового техпроцессов показаны не до конца — видимо, коммерческая тайна. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Стоимость постройки наиболее современного на указанный год завода (или его стоимость после обновления) возросла в 70 раз за 30 лет, а цена каждого выпускаемого ими транзистора упала в 2000 раз. Пустые квадраты означают примерные цифры. Тут не хватает графика производственной мощности, но надёжных данных по ней на весь период нет. Впрочем, известно, что современные фабы выпускают от 10 до 60 тыс. пластин в месяц в случае логики и ещё в 2–3 раза больше для памяти. Выпуск пластин удваивается примерно каждые 5 лет, помимо увеличения их диаметра. А «удвоение стоимости фаба каждые 4 года» даже было названо «вторым законом Мура» (иначе — законом Рока, Rock’s law), который в конце 90-х также пришлось поправить — каждые 5 лет. Наиболее дорогой станок — фотолитограф — дорожает с такой же скоростью: первый коммерческий проекционный степпер (1973 г.) стоил 210 тыс. долларов, а современный сканер — 40–50 млн.. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Удельные цены пластины и разных видов микросхем за единицу их наиболее ценных количественных характеристик. Чёрная линия указывает ежегодное падение средней цены на 35% или в 1,54 раза. Больше возможностей за ту же цену чипов позволяли расти продажам микросхем на 15% в год с 1960 по 2000 гг.. Однако лопнул пузырь доткомов, а через 8 лет грянул мировой кризис, что прекратило рост продаж (но не параметров). В 2010-х за счёт популярности смартфонов и планшетников возможен рост примерно на 5% в год, если, конечно, опять что-то не стрясётся… | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 Стоимость разработки сложной микросхемы в зависимости от технормы (данные IBS, GlobalFoundries). Видно, что до 45 нм она каждый раз удваивалась, а начиная с 45 нм — увеличивается примерно в 1,5 раза. Абсолютные цифры уже выросли настолько, что и среди бесфабричных компаний мелким игрокам на рынке ЦП делать нечего. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Средняя стоимость производства пластины для КМОП-логики в 2003 г. на фабах Сев. Америки (в долларах):
Цены округлены и не учитывают финишных операций (тестирования, резки и корпусировки). По цифрам видно, почему производителям выгодно переходить на новые техпроцессы и бо́льшие диаметры пластин — дорожание производства каждой новой пластины окупается бо́льшим числом получаемых с неё чипов. Впрочем, переход на больший диаметр означает замену почти всего оборудования в чистой комнате и усиление потока сверхчистых рабочих материалов (особенно воды), поставляемых с сервисного этажа. А переход на новый техпроцесс, даже «несвежий», поначалу (пока его не отладят) даст меньший выход годных. Впрочем, Intel и тут отличилась, применяя на своих фабах по всему миру методику точного копирования (Copy Exactly): как только техпроцесс доведён до массового производства на одном из экспериментальных фабов в Хиллсборо (штат Орегон, США), он переносится на производственные фабы, копируя абсолютно всё до мелочей — список и тип станков, их параметры («рецепты») и программы, действия персонала… Даже ручные инструменты для монтажных и пуско-наладочных работ используются тех же видов. Звучит несколько параноидально, но Intel может перенести техпроцесс с одной фабрики на другую без ожидаемого в таких случаях ущерба для себестоимости всего за несколько месяцев, и ещё быстрее — производство чипа при уже готовом техпроцессе. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||

В начале лета 2011 г. Intel объявила, что менее чем через год будет готова массово выпускать процессоры с технормой 22 нм (сначала это будет архитектура Ivy Bridge, основанная на современной Sandy Bridge). Согласно принятому в компании 2-летнему циклу «тик-так» (попеременному ежегодному выпуску новой микроархитектуры и нового техпроцесса) изначально планировалось выпустить Ivy Bridge в конце 2011 г. (также как Sandy Bridge — в 2010-м). Однако Intel преследуют задержки: презентация Sandy Bridge состоялась только этим январём, а недавно компания решила задержать выход Ivy Bridge как минимум до весны 2012 г.. Являются ли тому причиной сложности с техпроцессом — неясно. Это при том, что первые микросхемы СОЗУ с новыми 22-нанометровыми транзисторами Intel представила ещё в сентябре 2009 г..
Никаких технологических революций по части литографических методов не предвидится — помимо того, что длина волны 193 нм требует иметь не только иммерсионные сканеры, но и как минимум двойное шаблонирование. Это само по себе является любопытным, ибо ещё 5 лет назад эксперты в один голос говорили, что для таких длин волн надо переходить на новые виды литографии, что скачкообразно увеличивает сложность и стоимость техпроцесса.
 Помимо FinFET’ов, Intel рассматривала ещё 4 варианта новых видов транзисторов, но по разным причинам они были отклонены. Например, технически самый совершенный GAA-транзистор с затвором, полностью окружённым изолятором, видимо, показался слишком дорогим или ненадёжным. Кроме того, т. к. странная зелёная «шапка» ни на каких других иллюстрациях больше не встречается и не видна на микрофотографиях, можно сделать вывод, что реализован вариант с 3-сторонним затвором типа Trigate. |
Но самую большую сенсацию (разумеется, с подачи маркетологов компании) назначили на серьёзное изменение конструкции транзисторов, назвав их трёхмерными или трёхзатворными. Точнее, их надо называть FinFET — полевой транзистор с затвором-«плавником». Впрочем, за счёт утончения канала и размещения его вертикально их число может быть более одного для увеличения общей площади между затвором и каналами. Такой транзистор можно назвать многозатворным (multigate FET, MuGFET), хотя каждый его канал скорее будет управляться общим затвором. В результате к нему нужно будет приложить меньшее напряжение, чтобы переключить транзистор, скорость переключения будет больше, а утечка — меньше, т. к. теперь она возможна лишь через узкую нижнюю грань канала.
 Транзистор на цельной подложке (какую до сих пор использует Intel) имеет утечку тока из канала, когда в нём полем затвора формируется обращённый слой. Подложка (даже если она заземлена) вытягивает часть носителей заряда в обеднённый слой. ▼ |
 Уменьшить утечки можно технологией КНИ, в данном случае — частично обеднённой (Partially Depleted, PD SOI). Тут изолятор отсекает подложку, но остаточный слой под каналом («плавающее тело») всё ещё приводит к утечкам, хоть и не таким большим. Эта технология широко используется прежде всего из-за относительной дешевизны. ▼ |
 Более продвинутая версия — полностью обеднённый КНИ (Fully Depleted, FD SOI). Тут исток, сток и область канала истончаются так, что плавающему телу не остаётся места. Проблема утечки решается, но (по мнению Intel) с 10-процентным увеличением цены чипа, поэтому её не используют широко. ▼ |
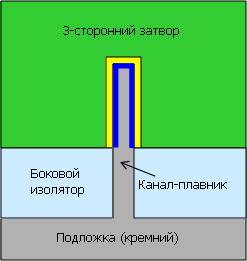 А вот и решение Intel (показанное сбоку, в отличие от предыдущих сечений вдоль канала) — поставить канал вертикально и окружить его затвором с трёх сторон из четырёх. Плавающего тела нет, утечек нет, площадь обращённого слоя больше, а т. к. дополнительные маски не требуются, цена — всего на 2–3% выше. Опять же, со слов Intel. |
 «Трёхзатворный» транзистор на деле означает транзистор с каналом, окружённым затвором (через прослойку в виде тонкого изолятора, обозначенного жёлтым) с трёх сторон — по сравнению с планарным, где поверхность сопряжения представляет собой одну плоскость. |
 Вверху показаны 32-нанометровые планарные транзисторы, внизу — 22-нанометровые 2- (в левом нижнем углу) и 6-затворные «трёхмерные». |
 4 поколения «плавниковых» транзисторов Intel — демонстрация конструкции (2002 г.), многозатворность (2003), ячейки СОЗУ (2006) и адаптация металлического «затвора последним» (2007). |
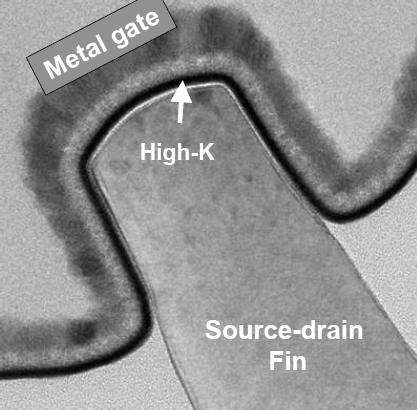 Сечение канала-плавника в образце 2006 г. с первой версией технологии HKMG. |
Конечно, Intel сразу похвасталась, что по сравнению с 10-микронным техпроцессом от i4004 22-нанометровый транзистор работает в 4000 раз быстрее, потребляя в 5000 меньше энергии и стоя в 50 000 меньше. Более важно, что потребовалось 5 лет для разработки и ещё 5 (как теперь выяснилось…) для адаптации к массовому производству. При этом Intel честно указывает на трудности реализации новой технологии: необходимость законцовок для затвора, проблемы с ёмкостью и изменчивостью параметров, трудности равномерной полировки и травления более толстых структур и передача каналом механического напряжения под затвор, и пр.. Надо полагать, все эти проблемы решены хотя бы удовлетворительно, иначе показанные чипы бы не работали. Вопросы о коэффициенте выхода годных и фактической себестоимости пока остаются открытыми. Конкуренты же (TSMC и Global Foundries) пока объявили лишь о начале разработки FinFET’ов для своих 14-нанометровых процессов, которые будут готовы где-то в 2014 г.…
Вольтамперные характеристики (ВАХ) планарного (чёрная линия) и двух трёхмерных (синие) n-канальных транзисторов. Ток при нуле на затворе в идеале должен быть нулевым. Чем он меньше — тем меньше потребляет процессор, в т. ч. при простое. Пороговое напряжение — такое, при котором транзистор переключается (в данном случае — 0,33 В с током в 10% от номинала). Оно должно быть как можно меньше, чтобы транзистор срабатывал быстрее и при меньшем напряжении питания (тут — 1 В). Переход на трёхмерный затвор позволяет либо при том же напряжении уменьшить утечку при закрытом канале (нижняя линия), либо увеличить скорость его открытия (верхняя линия), заодно снизив напряжение. | |
Зависимость времени переключения от напряжения питания (в идеале — гипербола) для 32-нанометровых (чёрная линия) и 22-нанометровых (серая) планарных, а также 22-нанометровых объёмного (синяя) транзисторов. Последний позволяет при той же скорости снизить напряжение питания на 0,2 В, что в теории уменьшит потребление в 1,56 раза, а по мнению Intel — более чем вдвое. Если же требуется повысить частоту, новые транзисторы принесут небольшую пользу при номинальном одном вольте (обещано ускорение на 18% относительно 32 нм), зато при 0,7 В (видимо, таково будет напряжение для мобильных чипов) дадут аж 37-процентное ускорение. Более того, если судить по этим графикам из презентации, то ускорения будут на 22% и 59% — т. е. 1/(1−0,18) и 1/(1−0,37), как и следует считать. Неужели мы застукали технарей Intel на элементарных ошибках при расчётах с процентами?.. |


Самое время разобраться, что понимается под технормой. Попытка дать определение этому важнейшему термину не зря поставлена почти в конец статьи. Когда-то под технормой понимался самый малый по длине или ширине элемент, формируемый данным техпроцессом. Когда технорма стала меньше длины волны, появилось два отдельных определения — для регулярных чипов (память, программируемые матрицы, фотодатчики — в т. ч. со встроенными логическими блоками) и нерегулярных (сложная логика, в т. ч. содержащая кэши, буферы и т. п.). Для первых — минимальный полушаг линейно-регулярной структуры, для вторых — минимальная ширина дорожки нижнего уровня металла (что примерно вдвое длиннее затвора транзистора).
Однако с недавних пор и это перестало иметь значение. Дело в том, что число фабрик, производящих микросхемы по самым современным техпроцессам, неуклонно снижается. При этом ни одна фирма, производящая оборудование для производства полупроводников, их самих не делает — все производители микросхем покупают станки у примерно одних (тоже не очень многочисленных) фирм. Очевидно, собираемые из станков и настроек техпроцессы на фабах получились бы как две капли воды похожи, но это имеет смысл лишь для нескольких фабов одной компании, а таких компаний в мире — единицы. Так что каждая фирма пытается удовлетворить заказчиков чем-то особенным, выпускаемым на почти стандартном оборудовании. И вот тут под нож пошли те самые нанометры…
² — С иммерсионной литографией ³ — С иммерсионной литографией и низкопроницаемыми межслойными диэлектриками |
В этой таблице указана площадь (в кв. микронах) 6-транзисторной ячейки СОЗУ, которой обычно меряют плотность размещения транзисторов для логических микросхем. (Это само по себе любопытно, учитывая, что СОЗУ используются в разнообразных регистрах, буферах и кэшах — т. е. одно-, а чаще даже двухмерно регулярных схемах, а не в синтезированной логике, почти не имеющей повторений. И тем не менее…) А самое главное, что это всё — «45-нанометровые» (как утверждают эти компании) процессы!
Более того, ITRS (International Technology Roadmap for Semiconductors — международный технологический план для [производителей] полупроводников, составляемый экспертами из крупнейших фирм и их ассоциаций) регулярно выпускает рекомендации по основным параметрам техпроцессов для микроэлектронных компаний, т. е. для самих себя. А теперь посмотрим, как эти рекомендации соблюдаются:
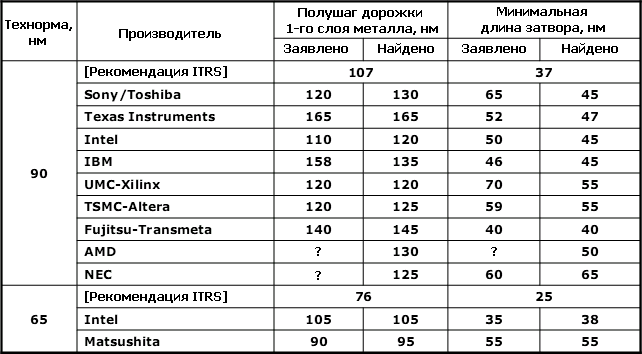 Рекомендации ITRS для логики в 2003 г. в сравнении с фактически найденными параметрами фирмой Chipworks, специализирующейся на «инженерной разборке» микросхем. |
Краткий ответ — никак. Дело дошло до того, что на недавнем форуме IEDM технорму признались считать маркетинговым понятием — т. е. не более чем цифрой для рекламы. Фактически, сегодня сравнивать техпроцессы по нанометрам стало не более разумно, чем 10 лет назад (после выхода Pentium 4) продолжать сравнивать производительность ЦП (пусть даже и одной программной архитектуры) по гигагерцам.
Разница в техпроцессах при одинаковых технормах активно влияет и на цену чипов. Например, AMD использовала разработанный совместно с IBM 65-нанометровый процесс с SOI-пластинами, двойными подзатворными оксидами, имплантированным в кремний германием, двумя видами напряжённых слоёв (сжимающим и растягивающим) и 10 слоями меди для межсоединений. 65-нанометровый техпроцесс у Intel включает относительно дешёвую пластину из цельного кремния, диэлектрик одинарной толщины, имплантированный в кремний германий, один растягивающий слой и 8 слоёв меди. По примерным подсчётам Intel потребует для своего процесса 31 маску, а AMD — 42.
В результате из-за значительной разницы в технологиях напряжённого кремния и типа подложки (SOI-пластины стоят примерно в 3,6 раз дороже простых) конечная цена 300-миллиметровой пластины для AMD будет ≈4300 долларов, что на 70% дороже цены для Intel — ≈2500 долларов. Кстати, ЦП Intel как правило оказываются ещё и с меньшими площадями кристаллов, чем аналогичные по числу ядер и размеру кэшей от AMD. Теперь ясно, почему Intel показывает завидную прибыль, а AMD недавно едва держалась на ногах.
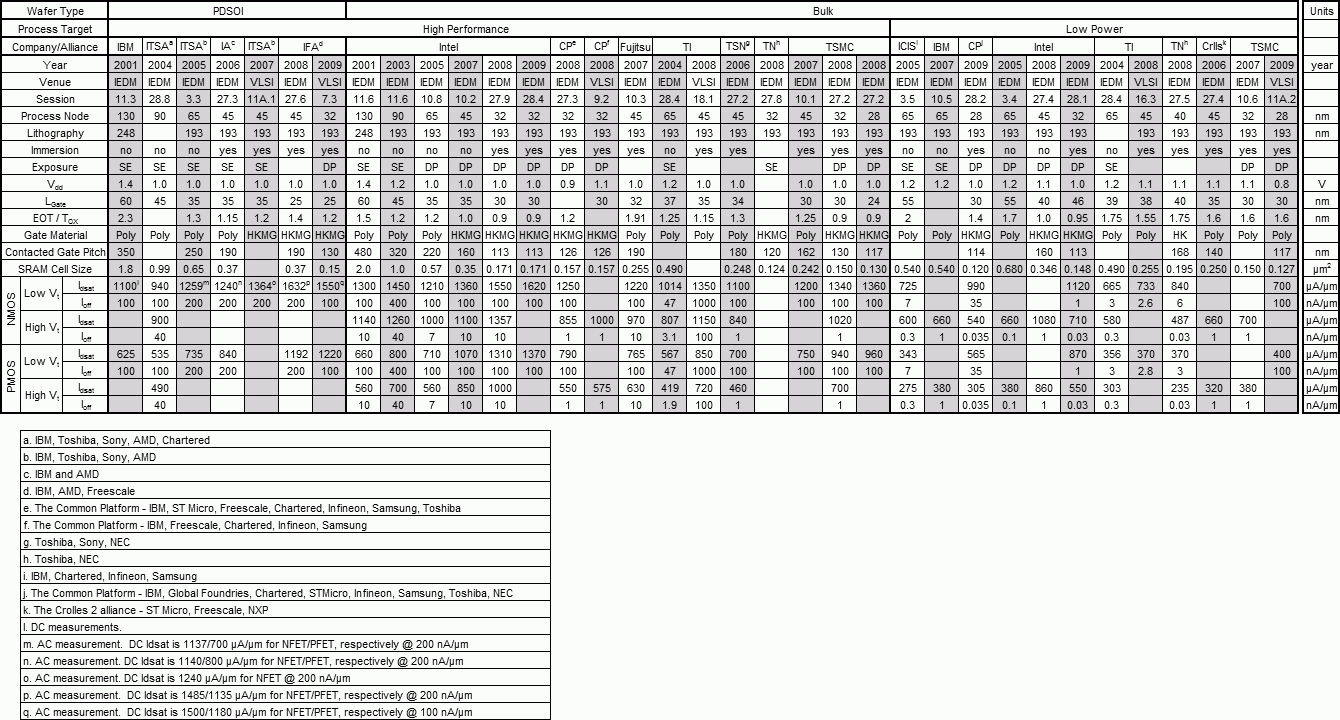 Данные с IEDM о техпроцессах к 2010 году. Источник — RealWorldTech. |
По докладам на IEDM можно составить сводную таблицу с параметрами последних техпроцессов ведущих компаний. Из неё видно, что все техпроцессы с «мелкой» технормой (process node) перешли на двойное шаблонирование (DP) и иммерсионную литографию, а напряжение питания (Vdd) давно остановилось на 1 вольте (потребление транзистором энергии и без этого продолжает падать, но не так быстро). Куда интересней сравнить длину затвора (LGate), шаг затвора с контактом (Contacted Gate Pitch) и площадь ячейки СОЗУ (SRAM Cell Size).
Тут надо указать, что кэши изготовленного с той же технормой ЦП той же фирмы имеют площадь ячейки на 5–15 % больше указанной в случае L2 и L3, и на 50–70 % больше для L1. Дело в том, что сообщаемые на IEDM цифры площади тоже являются несколько рекламными. Они верны лишь для одиночного массива ячеек и не учитывают усилители, буферы ввода-вывода, декодеры адреса, резервы размера для увеличения надёжности и размены плотности на скорость (для L1).
Для простоты возьмём только «скоростные» (High Performance) процессы Intel. Для 130 нм длина затвора составляла 46% технормы, а сегодня — 94%. Тем не менее, шаг затвора уменьшился в те же 4 раза, что и технорма. Однако если разделить площадь ячейки СОЗУ на квадрат технормы, то старым ячейкам нужно ≈120 таких квадратиков, а новым — уже ≈170. У AMD с её SOI-пластинами — примерно так же. На «65-нанометровом» техпроцессе фактический минимальный размер затвора может быть снижен до 25 нм, но шаг между затворами может превышать 130 нм, а минимальный шаг металлической дорожки — 180 нм. Начиная примерно с 2002 г. размеры транзисторов уменьшаются медленней технорм. Выражаясь языком современного рунета — нанометры уже не те…
А теперь, вооружившись цифрами об этом бардаке сложном микроэлектронном хозяйстве, вернёмся к обещанным Intel «22 нанометрам». По предварительным цифрам выглядит неплохо: площадь ячейки — 0,092 кв.мк. для «быстрой» и 0,108 для энергоэффективной версии процесса (данные 2009 г. для тестовой микросхемы СОЗУ на 22 нм). Для быстрой версии это эквивалентно 190 элементарным квадратам — чуть хуже, чем для прошлых технорм. Но Intel продолжит использовать 193-нанометровую иммерсионную литографию и для 14 нм, возможно — с тройным шаблонированием. А для 10 нм — с пятерным (5 экспозиций и одно скругление распорок). При этом для 10-нанометрового процесса стоимость стадий литографии на единицу площади будет примерно вшестеро больше, чем для 32-нанометрового, а вот окажется ли площадь меньше в 10 раз (как при линейном уменьшении) — сомнительно. Тут уже даже неважно, почему Intel решила, что следующие два её процесса будут иметь технормы 14 и 10 нм, а не 16 и 11, как можно ожидать (каждая следующая — в √2 раз меньше). Ведь нанометры теперь мало что значат… Что дальше?
Если вернуться к обзорным графикам, последние несколько из них не зря касаются цены или себестоимости. Если по ним попытаться экстраполировать тенденции на будущее, то окажется, что через некоторое время в мире останется лишь 2–3 компании, способные разрабатывать и внедрять самые современные техпроцессы. Им это будет влетать в 11-значные суммы в долларах, окупить которые можно, лишь если продукция будет продаваться по всему миру, что возможно только при полной монополизации — одна платформа, одна архитектура, одна концепция… Для необходимой конкуренции избыточности места уже не останется — нас всего 7 миллиардов, и это число растёт совсем не так быстро, как цены на фабы и техпроцессы.
Более того, наверняка будет уменьшаться и число бесфабричных компаний. Дело даже не в том, что немногие крупные фирмы покроют своими чипами почти все потребности почти для всех. Даже если вы разработали что-то уникальное — стоимость внедрения может оказаться такой высокой, что вы не окупите её всеми своими продажами. И это тоже есть следствие массовых технологий:
Формируемое маской изображение перед попаданием на пластину оптически уменьшается в 4 раза до стандартной полосы засвета размером ≈24 мм (для современных литографов), а размер самой маски составляет около 18×12 см. Однако методы OPC и PSM требуют от неё иметь разрешение не хуже формируемого, что уже для 65 нм поднимает стоимость набора масок до сотен тысяч долларов, а для самых новых техпроцессов — до пары миллионов.
Теперь представим, что нам — маленькой, но гордой фирме — надо выпустить систему-на-кристалле, разработанную для новых планшетов и смартфонов. Маркетологи говорят, что из-за сильной конкуренции со стороны угадайте-какой компании устройства с нашим ЦП точно купят 100 000 человек. Процессор на 28-нанометровом техпроцессе (более старый проиграет гонку прожорливости) будет иметь себестоимость около 15 долларов, но если учесть цену масок (пусть и разделённую на 100 000), то будет уже 35 долларов. И это не учитывая выпуск нескольких ревизий для исправления ошибок и оптимизации параметров. Ревизий для нового сложного чипа нужно штук пять — и для каждой (после первой) надо обновлять значительную долю масок из всего набора.
В итоге окажется, что даже не допуская ни одной ошибки в рыночной стратегии, мы окупим нашу микросхему, лишь рассчитывая на производство и сбыт устройств с ней миллионами, иначе её никто не купит из-за цены. Недавно сотрудник компании Cadence (выпускающей специализированные САПРы для разработки микросхем) рассказал, что стоимость перехода с 32–28 на 22–20 нм сильно выросла по сравнению с предыдущими шагами. Микроэлектронные компании инвестировали в НИОКР по 32–28 нм 1,2 млрд. долларов и 2–3 млрд. для 22–20 нм. Проектирование чипа стоит 50–90 млн. долларов для 32 нм и 120–500 млн. долларов для 22 нм. Компенсация затрат на разработку и производство потребует продать 30–40 млн. 32-нанометровых кристаллов и 60–100 млн. на 20 нм.
Впрочем, и крупным компаниям, товары которых покупают как раз миллионами, тоже придётся с трудом объяснять, зачем покупать очередной процессор с терафлопсами и память на терабайты — учитывая, что и прошлые модели делают всё как надо. Возможно, с некоторого момента не поможет и принудительная плата за новинки — например, как следствие досрочно отменённой поддержки старых моделей или их запрограммированного износа и отключения…
Мировая микроэлектроника, следуя закону Мура, всегда опровергала регулярно выдвигаемые инженерами опасения, что мы вот-вот упрёмся в непреодолимые физические ограничения, после которых отрасль либо застрянет навсегда, либо будет вынуждена перейти на принципиально новые материалы и эффекты. Но как бы не оказалось так, что реальным тормозом будет эффект глобального насыщения: после бурного роста менять каждые год-два процессоры и память как обувь и одежду — на новые, подходящие размеры — уже не потребуется.
Другая проблема в том, что даже в тех применениях, где производительность и память никогда не будут лишними, качественный скачок (вместо очередного удвоения регистров, векторов, кэшей и ядер) может быть лишь при переходе на новый вид элементной базы — графеновой, фотонной, спинтронной, квантовой или прочей «волшебной». Но для её разработки, адаптации к массовому производству и (особенно!) построению самого производства потребуется огромное количество денег — куда большее цены современного фаба. Вполне возможно, лет через 10 (когда нынешнюю литографию растягивать далее уже не получится) никакие частные фирмы это не потянут. А какое из государств даже сегодня захочет профинансировать высокорисковые технологии микроэлектроники будущего?
Автор выражает благодарность экспертам с форума iXBT.com за поправки и замечания.